
Princeton’s Algorithms Course
For the past 12 weeks I’ve been doing Princeton’s 2-part algorithms course which is available for free on coursera. These are my thoughts on the course (it’s excellent).
How the course works
Each week has 2 lessons at about 1 hour each. The lessons are videos with Robert Sedgewick narrating. Each week comes with an assignment to complete. The video materials are very good, covering the theory of an algorithm, implementation, and finally application. What I found extremely interesting was the application of algorithms to the real world problems. This aspect set it apart from algorithms course that I took for my diploma.
The Assignments
The assignments in this course are no joke. They streched my mind and my thinking about programming in general. The assignments are scored using an autograder - it firstly checks your correctness of code through thorough testing, then it checks the timing and memory. Each assignment has timing and memory constraints to hit, and if you want full marks, you have to be under those constraints.
With the grading system, I found it to almost be a game. I enjoyed submitting my code and waiting for my results. Striving for and getting the 100 points was immensely rewarding.
My Favourite assignments
Now I’ll share 3 of my favourite assignments.
Wordnet
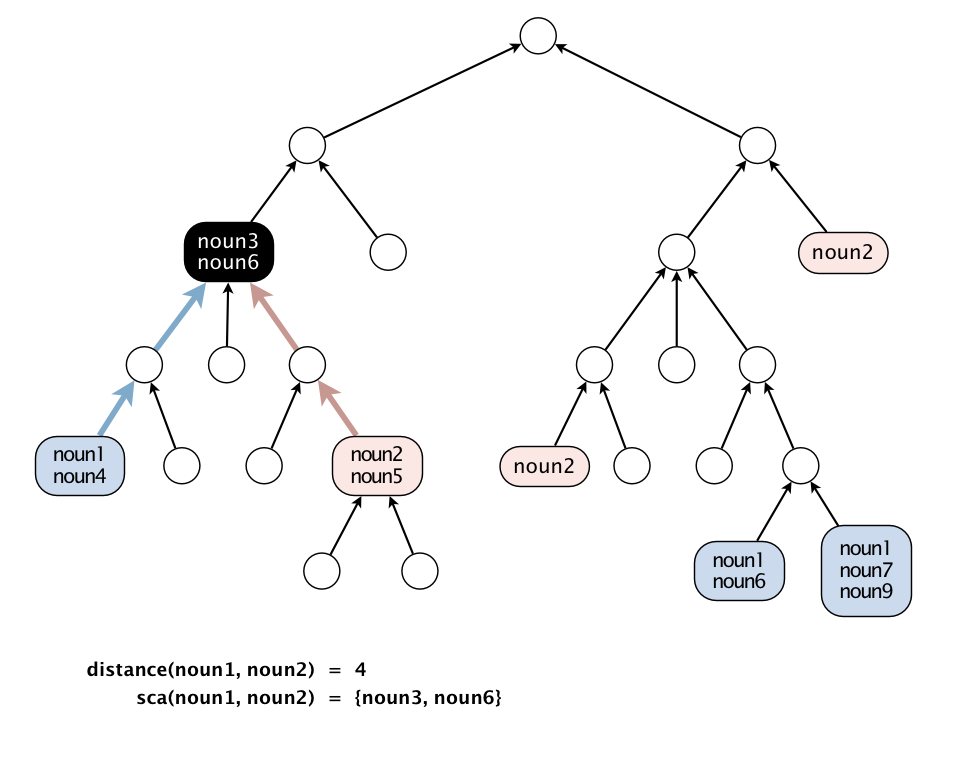
This assignment was to use a Digraph and create a representation of the Wordnet semantic lexicon. Then, 2 main operations would be performed. The first is to find the closest common ancestor to two different words. This would allow one to also measure the ‘relatedness’ of 2 words. The second operation is to find an outcast in a group of words - the one word least related to the other words in the group.
Implementing the first operation was tricky to me at first. I first used 2 isolated depth-first searches for the 2 nouns, using 1 boolean array marked[] to set if a certain index had been traversed. If one of the 2 depth first search instances reach an index which had been marked before, it is taken that a common ancestor had been found.
This worked in trivial cases. However, there were false positives if either of the vertexes contained a cycle. The search would go one whole cycle and encounter a marked vertex. Encountering this, I jumped through a bunch of hoops in order to detect a cycle. None of my solutions fit the time or memory constraint, and involved a level of complexity that I did not want. (I now know of an interesting algorithm to detect a cycle, though - Floyd’s tortoise and hare)
I got over this problem by realizing that by implementing the 2 DFSs in lockstep and using separate arrays to set marked indexes, there was no need for even doing cycle detection! One DFS checks the other’s marked[] array. Frustratingly simple looking back at it.
The last problem was getting it to run in proper time. This was where I learned a valuable lesson: not letting your program run any more than it has to. This was a simple fix, but it cut the running time of the program down by a massive amount. This was done by implementing early termination: if the next node in the current branch exceeds the current shortest distance, there is no point in proceeding any further.
So this assignment taught me a couple of valuable lessons.
Seam Carving
The application of algorithms for this assignment was really mind-blowing.
The assignment was to take in an image and calculate the energy for every pixel using the dual-gradient energy function. The next task is to find a vertical seam of minimum total energy.

In practice, this can be used to acheive image resizing without distorting key elements in the image by finding the minimum energy seam and deleting it repeatedly.

For this assignment, I implemented Djikstra’s Shortest Path algorithm, and ran it through the array of RGB pixels to find the path of shortest energy.
Boggle
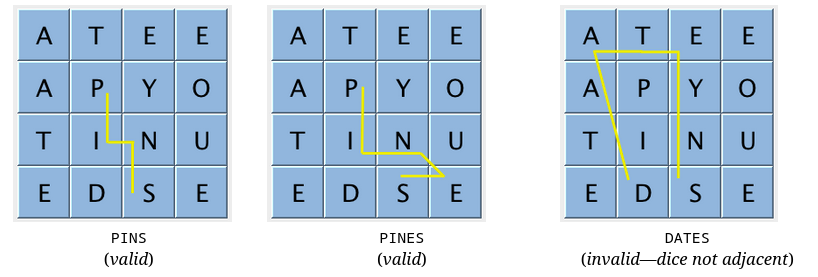
The goal of this assignment was to find all the valid words in a given Boggle board.
For this assignment I implemented the Trie data structure that contains all the words in a given dictionary. The code then traverses the whole board, checking for words that exist in that dictionary.
A key optimization that allowed me to hit the target timing was implementing early termination in situations where there is no point continuing to search the board. It also taught me that I can extend the functionality of common data structures to achieve better performance.
Conclusion
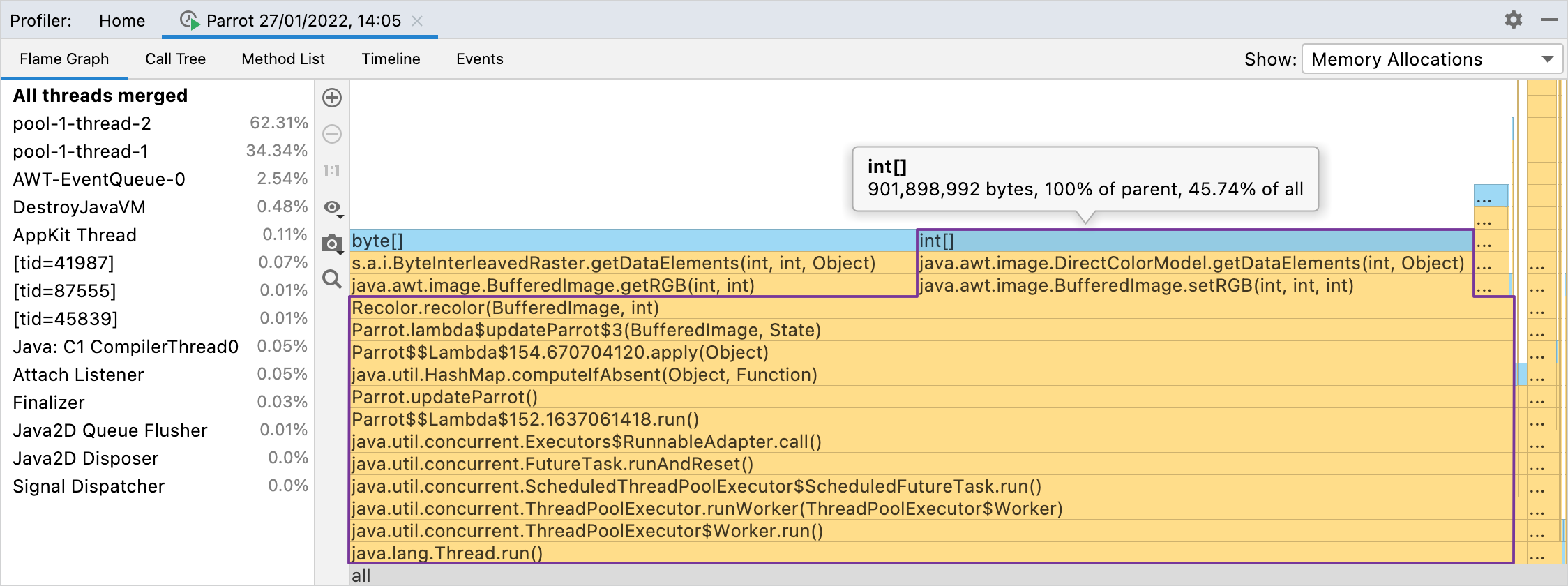
I loved this course, the assignments were really fun and insightful. It was such a rewarding experience trying to get 100 points for every assignment. I even learned how to use a profiler to improve the timings of my code for this course! Thank you to the computer GODS Robert Sedgewick and Kevin Wayne for making this course online and absolutely free. It is an amazing resource, and if any of the assignments sound interesting to you, I encourage checking it out!